- What is Data Interpretation?
- Understanding Data
- Exploratory Data Analysis: Unveiling Insights from Data
- Descriptive Statistics: Understanding Data’s Central Tendency and Variability
- Inferential Statistics: Drawing Inferences and Making Hypotheses
- Data Interpretation Techniques: Unlocking Insights for Informed Decisions
- Data Visualization Techniques: Communicating Insights Effectively
- Data Interpretation in Specific Domains: Unlocking Domain-Specific Insights
- Data Interpretation Tools and Software: Empowering Your Analysis
- Common Challenges and Pitfalls in Data Interpretation: Navigating the Data Maze
- Best Practices for Effective Data Interpretation: Making Informed Decisions
- Data Interpretation Examples: Applying Techniques to Real-World Scenarios
- Conclusion
In today’s data-driven world, the ability to interpret and extract valuable insights from data is crucial for making informed decisions. Data interpretation involves analyzing and making sense of data to uncover patterns, relationships, and trends that can guide strategic actions.
Whether you’re a business professional, researcher, or data enthusiast, this guide will equip you with the knowledge and techniques to master the art of data interpretation.
What is Data Interpretation?
Data interpretation is the process of analyzing and making sense of data to extract valuable insights and draw meaningful conclusions. It involves examining patterns, relationships, and trends within the data to uncover actionable information. Data interpretation goes beyond merely collecting and organizing data; it is about extracting knowledge and deriving meaningful implications from the data at hand.
Why is Data Interpretation Important?
In today’s data-driven world, data interpretation holds immense importance across various industries and domains. Here are some key reasons why data interpretation is crucial:
- Informed Decision-Making: Data interpretation enables informed decision-making by providing evidence-based insights. It helps individuals and organizations make choices supported by data-driven evidence, rather than relying on intuition or assumptions.
- Identifying Opportunities and Risks: Effective data interpretation helps identify opportunities for growth and innovation. By analyzing patterns and trends within the data, organizations can uncover new market segments, consumer preferences, and emerging trends. Simultaneously, data interpretation also helps identify potential risks and challenges that need to be addressed proactively.
- Optimizing Performance: By analyzing data and extracting insights, organizations can identify areas for improvement and optimize their performance. Data interpretation allows for identifying bottlenecks, inefficiencies, and areas of optimization across various processes, such as supply chain management, production, and customer service.
- Enhancing Customer Experience: Data interpretation plays a vital role in understanding customer behavior and preferences. By analyzing customer data, organizations can personalize their offerings, improve customer experience, and tailor marketing strategies to target specific customer segments effectively.
- Predictive Analytics and Forecasting: Data interpretation enables predictive analytics and forecasting, allowing organizations to anticipate future trends and make strategic plans accordingly. By analyzing historical data patterns, organizations can make predictions and forecast future outcomes, facilitating proactive decision-making and risk mitigation.
- Evidence-Based Research and Policy Making: In fields such as healthcare, social sciences, and public policy, data interpretation plays a crucial role in conducting evidence-based research and policy-making. By analyzing relevant data, researchers and policymakers can identify trends, assess the effectiveness of interventions, and make informed decisions that impact society positively.
- Competitive Advantage: Organizations that excel in data interpretation gain a competitive edge. By leveraging data insights, organizations can make informed strategic decisions, innovate faster, and respond promptly to market changes. This enables them to stay ahead of their competitors in today’s fast-paced business environment.
In summary, data interpretation is essential for leveraging the power of data and transforming it into actionable insights. It enables organizations and individuals to make informed decisions, identify opportunities and risks, optimize performance, enhance customer experience, predict future trends, and gain a competitive advantage in their respective domains.
The Role of Data Interpretation in Decision-Making Processes
Data interpretation plays a crucial role in decision-making processes across organizations and industries. It empowers decision-makers with valuable insights and helps guide their actions. Here are some key roles that data interpretation fulfills in decision-making:
- Informing Strategic Planning: Data interpretation provides decision-makers with a comprehensive understanding of the current state of affairs and the factors influencing their organization or industry. By analyzing relevant data, decision-makers can assess market trends, customer preferences, and competitive landscapes. These insights inform the strategic planning process, guiding the formulation of goals, objectives, and action plans.
- Identifying Problem Areas and Opportunities: Effective data interpretation helps identify problem areas and opportunities for improvement. By analyzing data patterns and trends, decision-makers can identify bottlenecks, inefficiencies, or underutilized resources. This enables them to address challenges and capitalize on opportunities, enhancing overall performance and competitiveness.
- Risk Assessment and Mitigation: Data interpretation allows decision-makers to assess and mitigate risks. By analyzing historical data, market trends, and external factors, decision-makers can identify potential risks and vulnerabilities. This understanding helps in developing risk management strategies and contingency plans to mitigate the impact of risks and uncertainties.
- Facilitating Evidence-Based Decision-Making: Data interpretation enables evidence-based decision-making by providing objective insights and factual evidence. Instead of relying solely on intuition or subjective opinions, decision-makers can base their choices on concrete data-driven evidence. This leads to more accurate and reliable decision-making, reducing the likelihood of biases or errors.
- Measuring and Evaluating Performance: Data interpretation helps decision-makers measure and evaluate the performance of various aspects of their organization. By analyzing key performance indicators (KPIs) and relevant metrics, decision-makers can track progress towards goals, assess the effectiveness of strategies and initiatives, and identify areas for improvement. This data-driven evaluation enables evidence-based adjustments and ensures that resources are allocated optimally.
- Enabling Predictive Analytics and Forecasting: Data interpretation plays a critical role in predictive analytics and forecasting. Decision-makers can analyze historical data patterns to make predictions and forecast future trends. This capability empowers organizations to anticipate market changes, customer behavior, and emerging opportunities. By making informed decisions based on predictive insights, decision-makers can stay ahead of the curve and proactively respond to future developments.
- Supporting Continuous Improvement: Data interpretation facilitates a culture of continuous improvement within organizations. By regularly analyzing data, decision-makers can monitor performance, identify areas for enhancement, and implement data-driven improvements. This iterative process of analyzing data, making adjustments, and measuring outcomes enables organizations to continuously refine their strategies and operations.
In summary, data interpretation is integral to effective decision-making. It informs strategic planning, identifies problem areas and opportunities, assesses and mitigates risks, facilitates evidence-based decision-making, measures performance, enables predictive analytics, and supports continuous improvement. By harnessing the power of data interpretation, decision-makers can make well-informed, data-driven decisions that lead to improved outcomes and success in their endeavors.
Understanding Data
Before delving into data interpretation, it’s essential to understand the fundamentals of data. Data can be categorized into qualitative and quantitative types, each requiring different analysis methods. Qualitative data represents non-numerical information, such as opinions or descriptions, while quantitative data consists of measurable quantities.
Types of Data
- Qualitative data: Includes observations, interviews, survey responses, and other subjective information.
- Quantitative data: Comprises numerical data collected through measurements, counts, or ratings.
Data Collection Methods
To perform effective data interpretation, you need to be aware of the various methods used to collect data. These methods can include surveys, experiments, observations, interviews, and more. Proper data collection techniques ensure the accuracy and reliability of the data.
Data Sources and Reliability
When working with data, it’s important to consider the source and reliability of the data. Reliable sources include official statistics, reputable research studies, and well-designed surveys. Assessing the credibility of the data source helps you determine its accuracy and validity.
Data Preprocessing and Cleaning
Before diving into data interpretation, it’s crucial to preprocess and clean the data to remove any inconsistencies or errors. This step involves identifying missing values, outliers, and data inconsistencies, as well as handling them appropriately. Data preprocessing ensures that the data is in a suitable format for analysis.
Exploratory Data Analysis: Unveiling Insights from Data
Exploratory Data Analysis (EDA) is a vital step in data interpretation, helping you understand the data’s characteristics and uncover initial insights. By employing various graphical and statistical techniques, you can gain a deeper understanding of the data patterns and relationships.
Univariate Analysis
Univariate analysis focuses on examining individual variables in isolation, revealing their distribution and basic characteristics. Here are some common techniques used in univariate analysis:
- Histograms: Graphical representations of the frequency distribution of a variable. Histograms display data in bins or intervals, providing a visual depiction of the data’s distribution.
- Box plots: Box plots summarize the distribution of a variable by displaying its quartiles, median, and any potential outliers. They offer a concise overview of the data’s central tendency and spread.
- Frequency distributions: Tabular representations that show the number of occurrences or frequencies of different values or ranges of a variable.
Bivariate Analysis
Bivariate analysis explores the relationship between two variables, examining how they interact and influence each other. By visualizing and analyzing the connections between variables, you can identify correlations and patterns. Some common techniques for bivariate analysis include:
- Scatter plots: Graphical representations that display the relationship between two continuous variables. Scatter plots help identify potential linear or nonlinear associations between the variables.
- Correlation analysis: Statistical measure of the strength and direction of the relationship between two variables. Correlation coefficients, such as Pearson’s correlation coefficient, range from -1 to 1, with higher absolute values indicating stronger correlations.
- Heatmaps: Visual representations that use color intensity to show the strength of relationships between two categorical variables. Heatmaps help identify patterns and associations between variables.
Multivariate Analysis
Multivariate analysis involves the examination of three or more variables simultaneously. This analysis technique provides a deeper understanding of complex relationships and interactions among multiple variables. Some common methods used in multivariate analysis include:
- Dimensionality reduction techniques: Approaches like Principal Component Analysis (PCA) or t-Distributed Stochastic Neighbor Embedding (t-SNE) reduce high-dimensional data into lower dimensions, simplifying analysis and visualization.
- Cluster analysis: Grouping data points based on similarities or dissimilarities. Cluster analysis helps identify patterns or subgroups within the data.
Descriptive Statistics: Understanding Data’s Central Tendency and Variability
Descriptive statistics provides a summary of the main features of a dataset, focusing on measures of central tendency and variability. These statistics offer a comprehensive overview of the data’s characteristics and aid in understanding its distribution and spread.
Measures of Central Tendency
Measures of central tendency describe the central or average value around which the data tends to cluster. Here are some commonly used measures of central tendency:
- Mean: The arithmetic average of a dataset, calculated by summing all values and dividing by the total number of observations.
- Median: The middle value in a dataset when arranged in ascending or descending order. The median is less sensitive to extreme values than the mean.
- Mode: The most frequently occurring value in a dataset.
Measures of Dispersion
Measures of dispersion quantify the spread or variability of the data points. Understanding variability is essential for assessing the data’s reliability and drawing meaningful conclusions. Common measures of dispersion include:
- Range: The difference between the maximum and minimum values in a dataset, providing a simple measure of spread.
- Variance: The average squared deviation from the mean, measuring the dispersion of data points around the mean.
- Standard Deviation: The square root of the variance, representing the average distance between each data point and the mean.
Percentiles and Quartiles
Percentiles and quartiles divide the dataset into equal parts, allowing you to understand the distribution of values within specific ranges. They provide insights into the relative position of individual data points in comparison to the entire dataset.
- Percentiles: Divisions of data into 100 equal parts, indicating the percentage of values that fall below a given value. The median corresponds to the 50th percentile.
- Quartiles: Divisions of data into four equal parts, denoted as the first quartile (Q1), median (Q2), and third quartile (Q3). The interquartile range (IQR) measures the spread between Q1 and Q3.
Skewness and Kurtosis
Skewness and kurtosis measure the shape and distribution of data. They provide insights into the symmetry, tail heaviness, and peakness of the distribution.
- Skewness: Measures the asymmetry of the data distribution. Positive skewness indicates a longer tail on the right side, while negative skewness suggests a longer tail on the left side.
- Kurtosis: Measures the peakedness or flatness of the data distribution. Positive kurtosis indicates a sharper peak and heavier tails, while negative kurtosis suggests a flatter peak and lighter tails.
Inferential Statistics: Drawing Inferences and Making Hypotheses
Inferential statistics involves making inferences and drawing conclusions about a population based on a sample of data. It allows you to generalize findings beyond the observed data and make predictions or test hypotheses. This section covers key techniques and concepts in inferential statistics.
Hypothesis Testing
Hypothesis testing involves making statistical inferences about population parameters based on sample data. It helps determine the validity of a claim or hypothesis by examining the evidence provided by the data. The hypothesis testing process typically involves the following steps:
- Formulate hypotheses: Define the null hypothesis (H0) and alternative hypothesis (Ha) based on the research question or claim.
- Select a significance level: Determine the acceptable level of error (alpha) to guide the decision-making process.
- Collect and analyze data: Gather and analyze the sample data using appropriate statistical tests.
- Calculate the test statistic: Compute the test statistic based on the selected test and the sample data.
- Determine the critical region: Identify the critical region based on the significance level and the test statistic’s distribution.
- Make a decision: Compare the test statistic with the critical region and either reject or fail to reject the null hypothesis.
- Draw conclusions: Interpret the results and make conclusions based on the decision made in the previous step.
Confidence Intervals
Confidence intervals provide a range of values within which the population parameter is likely to fall. They quantify the uncertainty associated with estimating population parameters based on sample data. The construction of a confidence interval involves:
- Select a confidence level: Choose the desired level of confidence, typically expressed as a percentage (e.g., 95% confidence level).
- Compute the sample statistic: Calculate the sample statistic (e.g., sample mean) from the sample data.
- Determine the margin of error: Determine the margin of error, which represents the maximum likely distance between the sample statistic and the population parameter.
- Construct the confidence interval: Establish the upper and lower bounds of the confidence interval using the sample statistic and the margin of error.
- Interpret the confidence interval: Interpret the confidence interval in the context of the problem, acknowledging the level of confidence and the potential range of population values.
Parametric and Non-parametric Tests
In inferential statistics, different tests are used based on the nature of the data and the assumptions made about the population distribution. Parametric tests assume specific population distributions, such as the normal distribution, while non-parametric tests make fewer assumptions. Some commonly used parametric and non-parametric tests include:
- Parametric tests:
- Non-parametric tests:
- Mann-Whitney U test: Compare medians between two independent groups.
- Kruskal-Wallis test: Compare medians among multiple independent groups.
- Spearman’s rank correlation: Measure the strength and direction of monotonic relationships between variables.
Correlation and Regression Analysis
Correlation and regression analysis explore the relationship between variables, helping understand how changes in one variable affect another. These analyses are particularly useful in predicting and modeling outcomes based on explanatory variables.
- Correlation analysis: Determines the strength and direction of the linear relationship between two continuous variables using correlation coefficients, such as Pearson’s correlation coefficient.
- Regression analysis: Models the relationship between a dependent variable and one or more independent variables, allowing you to estimate the impact of the independent variables on the dependent variable. It provides insights into the direction, magnitude, and significance of these relationships.
Data Interpretation Techniques: Unlocking Insights for Informed Decisions
Data interpretation techniques enable you to extract actionable insights from your data, empowering you to make informed decisions. We’ll explore key techniques that facilitate pattern recognition, trend analysis, comparative analysis, predictive modeling, and causal inference.
Pattern Recognition and Trend Analysis
Identifying patterns and trends in data helps uncover valuable insights that can guide decision-making. Several techniques aid in recognizing patterns and analyzing trends:
- Time series analysis: Analyzes data points collected over time to identify recurring patterns and trends.
- Moving averages: Smooths out fluctuations in data, highlighting underlying trends and patterns.
- Seasonal decomposition: Separates a time series into its seasonal, trend, and residual components.
- Cluster analysis: Groups similar data points together, identifying patterns or segments within the data.
- Association rule mining: Discovers relationships and dependencies between variables, uncovering valuable patterns and trends.
Comparative Analysis
Comparative analysis involves comparing different subsets of data or variables to identify similarities, differences, or relationships. This analysis helps uncover insights into the factors that contribute to variations in the data.
- Cross-tabulation: Compares two or more categorical variables to understand the relationships and dependencies between them.
- ANOVA (Analysis of Variance): Assesses differences in means among multiple groups to identify significant variations.
- Comparative visualizations: Graphical representations, such as bar charts or box plots, help compare data across categories or groups.
Predictive Modeling and Forecasting
Predictive modeling uses historical data to build mathematical models that can predict future outcomes. This technique leverages machine learning algorithms to uncover patterns and relationships in data, enabling accurate predictions.
- Regression models: Build mathematical equations to predict the value of a dependent variable based on independent variables.
- Time series forecasting: Utilizes historical time series data to predict future values, considering factors like trend, seasonality, and cyclical patterns.
- Machine learning algorithms: Employ advanced algorithms, such as decision trees, random forests, or neural networks, to generate accurate predictions based on complex data patterns.
Causal Inference and Experimentation
Causal inference aims to establish cause-and-effect relationships between variables, helping determine the impact of certain factors on an outcome. Experimental design and controlled studies are essential for establishing causal relationships.
- Randomized controlled trials (RCTs): Divide participants into treatment and control groups to assess the causal effects of an intervention.
- Quasi-experimental designs: Apply treatment to specific groups, allowing for some level of control but not full randomization.
- Difference-in-differences analysis: Compares changes in outcomes between treatment and control groups before and after an intervention or treatment.
Data Visualization Techniques: Communicating Insights Effectively
Data visualization is a powerful tool for presenting data in a visually appealing and informative manner. Visual representations help simplify complex information, enabling effective communication and understanding.
Importance of Data Visualization
Data visualization serves multiple purposes in data interpretation and analysis. It allows you to:
- Simplify complex data: Visual representations simplify complex information, making it easier to understand and interpret.
- Spot patterns and trends: Visualizations help identify patterns, trends, and anomalies that may not be apparent in raw data.
- Communicate insights: Visualizations are effective in conveying insights to different stakeholders and audiences.
- Support decision-making: Well-designed visualizations facilitate informed decision-making by providing a clear understanding of the data.
Choosing the Right Visualization Method
Selecting the appropriate visualization method is crucial to effectively communicate your data. Different types of data and insights are best represented using specific visualization techniques. Consider the following factors when choosing a visualization method:
- Data type: Determine whether the data is categorical, ordinal, or numerical.
- Insights to convey: Identify the key messages or patterns you want to communicate.
- Audience and context: Consider the knowledge level and preferences of the audience, as well as the context in which the visualization will be presented.
Common Data Visualization Tools and Software
Several tools and software applications simplify the process of creating visually appealing and interactive data visualizations. Some widely used tools include:
- Tableau: A powerful business intelligence and data visualization tool that allows you to create interactive dashboards, charts, and maps.
- Power BI: Microsoft’s business analytics tool that enables data visualization, exploration, and collaboration.
- Python libraries: Matplotlib, Seaborn, and Plotly are popular Python libraries for creating static and interactive visualizations.
- R programming: R offers a wide range of packages, such as ggplot2 and Shiny, for creating visually appealing data visualizations.
Best Practices for Creating Effective Visualizations
Creating effective visualizations requires attention to design principles and best practices. By following these guidelines, you can ensure that your visualizations effectively communicate insights:
- Simplify and declutter: Eliminate unnecessary elements, labels, or decorations that may distract from the main message.
- Use appropriate chart types: Select chart types that best represent your data and the relationships you want to convey.
- Highlight important information: Use color, size, or annotations to draw attention to key insights or trends in your data.
- Ensure readability and accessibility: Use clear labels, appropriate font sizes, and sufficient contrast to make your visualizations easily readable.
- Tell a story: Organize your visualizations in a logical order and guide the viewer’s attention to the most important aspects of the data.
- Iterate and refine: Continuously refine and improve your visualizations based on feedback and testing.
Data Interpretation in Specific Domains: Unlocking Domain-Specific Insights
Data interpretation plays a vital role across various industries and domains. Let’s explore how data interpretation is applied in specific fields, providing real-world examples and applications.
Marketing and Consumer Behavior
In the marketing field, data interpretation helps businesses understand consumer behavior, market trends, and the effectiveness of marketing campaigns. Key applications include:
- Customer segmentation: Identifying distinct customer groups based on demographics, preferences, or buying patterns.
- Market research: Analyzing survey data or social media sentiment to gain insights into consumer opinions and preferences.
- Campaign analysis: Assessing the impact and ROI of marketing campaigns through data analysis and interpretation.
Financial Analysis and Investment Decisions
Data interpretation is crucial in financial analysis and investment decision-making. It enables the identification of market trends, risk assessment, and portfolio optimization. Key applications include:
- Financial statement analysis: Interpreting financial statements to assess a company’s financial health, profitability, and growth potential.
- Risk analysis: Evaluating investment risks by analyzing historical data, market trends, and financial indicators.
- Portfolio management: Utilizing data analysis to optimize investment portfolios based on risk-return trade-offs and diversification.
Healthcare and Medical Research
Data interpretation plays a significant role in healthcare and medical research, aiding in understanding patient outcomes, disease patterns, and treatment effectiveness. Key applications include:
- Clinical trials: Analyzing clinical trial data to assess the safety and efficacy of new treatments or interventions.
- Epidemiological studies: Interpreting population-level data to identify disease risk factors and patterns.
- Healthcare analytics: Leveraging patient data to improve healthcare delivery, optimize resource allocation, and enhance patient outcomes.
Social Sciences and Public Policy
Data interpretation is integral to social sciences and public policy, informing evidence-based decision-making and policy formulation. Key applications include:
- Survey analysis: Interpreting survey data to understand public opinion, social attitudes, and behavior patterns.
- Policy evaluation: Analyzing data to assess the effectiveness and impact of public policies or interventions.
- Crime analysis: Utilizing data interpretation techniques to identify crime patterns, hotspots, and trends, aiding law enforcement and policy formulation.
Data Interpretation Tools and Software: Empowering Your Analysis
Several software tools facilitate data interpretation, analysis, and visualization, providing a range of features and functionalities. Understanding and leveraging these tools can enhance your data interpretation capabilities.
Spreadsheet Software
Spreadsheet software like Excel and Google Sheets offer a wide range of data analysis and interpretation functionalities. These tools allow you to:
- Perform calculations: Use formulas and functions to compute descriptive statistics, create pivot tables, or analyze data.
- Visualize data: Create charts, graphs, and tables to visualize and summarize data effectively.
- Manipulate and clean data: Utilize built-in functions and features to clean, transform, and preprocess data.
Statistical Software
Statistical software packages, such as R and Python, provide a more comprehensive and powerful environment for data interpretation. These tools offer advanced statistical analysis capabilities, including:
- Data manipulation: Perform data transformations, filtering, and merging to prepare data for analysis.
- Statistical modeling: Build regression models, conduct hypothesis tests, and perform advanced statistical analyses.
- Visualization: Generate high-quality visualizations and interactive plots to explore and present data effectively.
Business Intelligence Tools
Business intelligence (BI) tools, such as Tableau and Power BI, enable interactive data exploration, analysis, and visualization. These tools provide:
- Drag-and-drop functionality: Easily create interactive dashboards, reports, and visualizations without extensive coding.
- Data integration: Connect to multiple data sources and perform data blending for comprehensive analysis.
- Real-time data analysis: Analyze and visualize live data streams for up-to-date insights and decision-making.
Data Mining and Machine Learning Tools
Data mining and machine learning tools offer advanced algorithms and techniques for extracting insights from complex datasets. Some popular tools include:
- Python libraries: Scikit-learn, TensorFlow, and PyTorch provide comprehensive machine learning and data mining functionalities.
- R packages: Packages like caret, randomForest, and xgboost offer a wide range of algorithms for predictive modeling and data mining.
- Big data tools: Apache Spark, Hadoop, and Apache Flink provide distributed computing frameworks for processing and analyzing large-scale datasets.
Common Challenges and Pitfalls in Data Interpretation: Navigating the Data Maze
Data interpretation comes with its own set of challenges and potential pitfalls. Being aware of these challenges can help you avoid common errors and ensure the accuracy and validity of your interpretations.
Sampling Bias and Data Quality Issues
Sampling bias occurs when the sample data is not representative of the population, leading to biased interpretations. Common types of sampling bias include selection bias, non-response bias, and volunteer bias. To mitigate these issues, consider:
- Random sampling: Implement random sampling techniques to ensure representativeness.
- Sample size: Use appropriate sample sizes to reduce sampling errors and increase the accuracy of interpretations.
- Data quality checks: Scrutinize data for completeness, accuracy, and consistency before analysis.
Overfitting and Spurious Correlations
Overfitting occurs when a model fits the noise or random variations in the data instead of the underlying patterns. Spurious correlations, on the other hand, arise when variables appear to be related but are not causally connected. To avoid these issues:
- Use appropriate model complexity: Avoid overcomplicating models and select the level of complexity that best fits the data.
- Validate models: Test the model’s performance on unseen data to ensure generalizability.
- Consider causal relationships: Be cautious in interpreting correlations and explore causal mechanisms before inferring causation.
Misinterpretation of Statistical Results
Misinterpretation of statistical results can lead to inaccurate conclusions and misguided actions. Common pitfalls include misreading p-values, misinterpreting confidence intervals, and misattributing causality. To prevent misinterpretation:
- Understand statistical concepts: Familiarize yourself with key statistical concepts, such as p-values, confidence intervals, and effect sizes.
- Provide context: Consider the broader context, study design, and limitations when interpreting statistical results.
- Consult experts: Seek guidance from statisticians or domain experts to ensure accurate interpretation.
Simpson’s Paradox and Confounding Variables
Simpson’s paradox occurs when a trend or relationship observed within subgroups of data reverses when the groups are combined. Confounding variables, or lurking variables, can distort or confound the interpretation of relationships between variables. To address these challenges:
- Account for confounding variables: Identify and account for potential confounders when analyzing relationships between variables.
- Analyze subgroups: Analyze data within subgroups to identify patterns and trends, ensuring the validity of interpretations.
- Contextualize interpretations: Consider the potential impact of confounding variables and provide nuanced interpretations.
Best Practices for Effective Data Interpretation: Making Informed Decisions
Effective data interpretation relies on following best practices throughout the entire process, from data collection to drawing conclusions. By adhering to these best practices, you can enhance the accuracy and validity of your interpretations.
Clearly Define Research Questions and Objectives
Before embarking on data interpretation, clearly define your research questions and objectives. This clarity will guide your analysis, ensuring you focus on the most relevant aspects of the data.
Use Appropriate Statistical Methods for the Data Type
Select the appropriate statistical methods based on the nature of your data. Different data types require different analysis techniques, so choose the methods that best align with your data characteristics.
Conduct Sensitivity Analysis and Robustness Checks
Perform sensitivity analysis and robustness checks to assess the stability and reliability of your results. Varying assumptions, sample sizes, or methodologies can help validate the robustness of your interpretations.
Communicate Findings Accurately and Effectively
When communicating your data interpretations, consider your audience and their level of understanding. Present your findings in a clear, concise, and visually appealing manner to effectively convey the insights derived from your analysis.
Data Interpretation Examples: Applying Techniques to Real-World Scenarios
To gain a better understanding of how data interpretation techniques can be applied in practice, let’s explore some real-world examples. These examples demonstrate how different industries and domains leverage data interpretation to extract meaningful insights and drive decision-making.
Example 1: Retail Sales Analysis
A retail company wants to analyze its sales data to uncover patterns and optimize its marketing strategies. By applying data interpretation techniques, they can:
- Perform sales trend analysis: Analyze sales data over time to identify seasonal patterns, peak sales periods, and fluctuations in customer demand.
- Conduct customer segmentation: Segment customers based on purchase behavior, demographics, or preferences to personalize marketing campaigns and offers.
- Analyze product performance: Examine sales data for each product category to identify top-selling items, underperforming products, and opportunities for cross-selling or upselling.
- Evaluate marketing campaigns: Analyze the impact of marketing initiatives on sales by comparing promotional periods, advertising channels, or customer responses.
- Forecast future sales: Utilize historical sales data and predictive models to forecast future sales trends, helping the company optimize inventory management and resource allocation.
Example 2: Healthcare Outcome Analysis
A healthcare organization aims to improve patient outcomes and optimize resource allocation. Through data interpretation, they can:
- Analyze patient data: Extract insights from electronic health records, medical history, and treatment outcomes to identify factors impacting patient outcomes.
- Identify risk factors: Analyze patient populations to identify common risk factors associated with specific medical conditions or adverse events.
- Conduct comparative effectiveness research: Compare different treatment methods or interventions to assess their impact on patient outcomes and inform evidence-based treatment decisions.
- Optimize resource allocation: Analyze healthcare utilization patterns to allocate resources effectively, optimize staffing levels, and improve operational efficiency.
- Evaluate intervention effectiveness: Analyze intervention programs to assess their effectiveness in improving patient outcomes, such as reducing readmission rates or hospital-acquired infections.
Example 3: Financial Investment Analysis
An investment firm wants to make data-driven investment decisions and assess portfolio performance. By applying data interpretation techniques, they can:
- Perform market trend analysis: Analyze historical market data, economic indicators, and sector performance to identify investment opportunities and predict market trends.
- Conduct risk analysis: Assess the risk associated with different investment options by analyzing historical returns, volatility, and correlations with market indices.
- Perform portfolio optimization: Utilize quantitative models and optimization techniques to construct diversified portfolios that maximize returns while managing risk.
- Monitor portfolio performance: Analyze portfolio returns, compare them against benchmarks, and conduct attribution analysis to identify the sources of portfolio performance.
- Perform scenario analysis: Assess the impact of potential market scenarios, economic changes, or geopolitical events on investment portfolios to inform risk management strategies.
These examples illustrate how data interpretation techniques can be applied across various industries and domains. By leveraging data effectively, organizations can unlock valuable insights, optimize strategies, and make informed decisions that drive success.
Conclusion
Data interpretation is a fundamental skill for unlocking the power of data and making informed decisions. By understanding the various techniques, best practices, and challenges in data interpretation, you can confidently navigate the complex landscape of data analysis and uncover valuable insights.
As you embark on your data interpretation journey, remember to embrace curiosity, rigor, and a continuous learning mindset. The ability to extract meaningful insights from data will empower you to drive positive change in your organization or field.
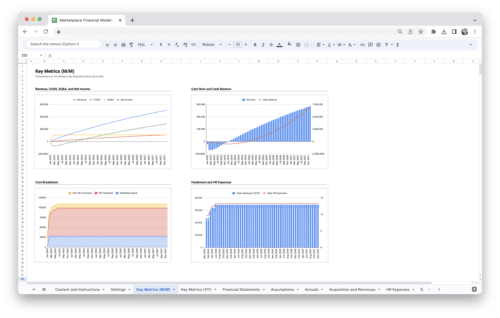
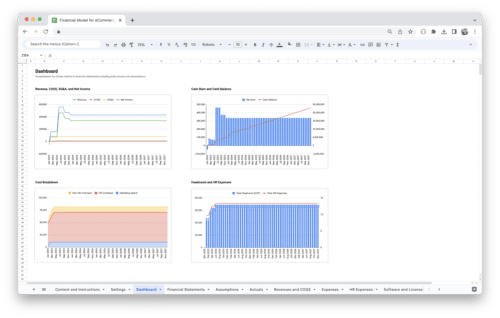
Get Started With a Prebuilt Template!
Looking to streamline your business financial modeling process with a prebuilt customizable template? Say goodbye to the hassle of building a financial model from scratch and get started right away with one of our premium templates.
- Save time with no need to create a financial model from scratch.
- Reduce errors with prebuilt formulas and calculations.
- Customize to your needs by adding/deleting sections and adjusting formulas.
- Automatically calculate key metrics for valuable insights.
- Make informed decisions about your strategy and goals with a clear picture of your business performance and financial health.